Introduction to Python
22 Oct 2013I did a quick presentation tonight for the Chattanooga Python Users Group.
introduction_to_python
Security, Programming, Pentesting
I did a quick presentation tonight for the Chattanooga Python Users Group.
introduction_to_python
The other day my friend Slade asked me to write a script to take an address range and run an Nmap ping scan against it and then run a SYN scan against only the live hosts using a predefined set of ports. Finally, he wanted a simple output showing the hosts and only the open ports. So, I put together this short Python script. The usage is below:
USAGE: discover.py IP_addresses ' Addresses must be a valid Nmap IP address range and ports must be a valid Nmap port list. Any ports provided will be added to the default ports that are scanned: 21, 22, 23, 25, 53, 80, 110, 119, 143, 443, 135, 139, 445, 593, 1352, 1433, 1498, 1521, 3306, 5432, 389, 1494, 1723, 2049, 2598, 3389, 5631, 5800, 5900, and 6000. The script should be run with root privileges.
The script uses the -oA switch to save the Nmap results for both the ping scan and the SYN scan. The gnmap file from the SYN scan is then parsed to produce a simple Markdown file that looks like this:
192.168.1.2 =========== OS -- HP Officejet J4680 printer|HP PhotoSmart C390 or C4780; or Officejet 6500, 7000, or 8500 printer|HP Photosmart C4500 or C7280, or Officejet J6450 printer Ports ----- tcp/80 (open) - Virata-EmWeb 6.2.1 (HP Photosmart C4700 series printer http config) tcp/ 139 (open) - tcpwrapped tcp/ 445 (open) - netbios-ssn 192.168.1.1 =========== OS -- Apple AirPort Extreme WAP or Time Capsule NAS device (NetBSD 4.99), or QNX 6.5.0 Ports ----- tcp/53 (open) - domain?
In addition to the discover.py script, I created the gnmap2md.py script which converts gnmap formatted files into Markdown formatted files. You can get it here.
As always, I hope you enjoy the script and let me know if you have any trouble with it.
This weekend we had a technology meetup at the 4thfloor in the downtown branch of the Chattanooga Library. We had a good turn out and I was able to talk about two of my favorite subjects, Python and infosec.
Here's the presentation I gave on the Requests library for Python.
The other day I needed to brute force an HTTP basic auth login so I fired up Metasploit, as I usually do, and and tried to run the auxiliary/scanner/http/http_login module. The module crashed and printed out a stack trace. Instead of spending time troubleshooting it, I decided to throw together a quick Python script. So I used my multiprocessor SSH brute force script as a template and put together a multiprocessor basic auth script. Well the next day, I needed to brute force an HTML login form so I decided to write Python script to do that as well.
HTTP Basic Auth is quite easy to brute force because after the credentials are sent, the server responds with a 401 status code if they were the wrong credentials and either a 2xx or 3xx status code if they were correct. HTML login forms are much more difficult because there are often cookies that must be set and hidden fields that are included in the form, typically for CSRF purposes. In addition, the body of the server response must be parsed to determine if the login failed or succeeded. So, brute forcing an HTML login forms follows a pattern like this.
I built a script that can automate the process but it does require some manual intervention in the form of a configuration file. The configuration file can be seen below and is in JSON format. First, set the login URL and the action URL, this is where the form gets POSTed. Next, set the field name for the username and password and set the files that contain the list of usernames and passwords to try. Next, set the string of text that will be in the failure message and set the number of threads that should be used. Finally, define the names of any hidden fields that should be included in the login form.
{
"login": "https://domain/login/url",
"action": "https://domain/login/action",
"ufield": "login",
"pfield": "password",
"ufile": "user",
"pfile": "pass",
"fail_str": "Some string that shows our login failed",
"threads": "1",
"hidden": [
"hidden_field_name1", "hidden_field_name2"
]
}
The script will first GET the login page defined in the config file, set any necessary cookies, and parse the page for the values of the hidden fields defined in the config file. Next, the script POSTs the login credentials and the hidden fields with their values to the action page defined in the config file. Finally, the response is parsed to find the failure string and to update the value of any hidden fields. If the failure string is present in the response, the process is repeated with a new set of credentials. If not, the script will stop and print the credentials that succeeded.
The script and a sample configuration file can be downloaded from the Scripts repository on my GitHub account, https://github.com/averagesecurityguy/scripts. As always, let me know if you have any questions or trouble running the script.
I do not use Facebook and after a few years, I finally convinced my wife to give it up. In my opinion, the social benefits of Facebook are far outweighed by the privacy and security concerns. To demonstrate, my father-in-law recently received a phishing message through facebookmail, see the screenshot below.
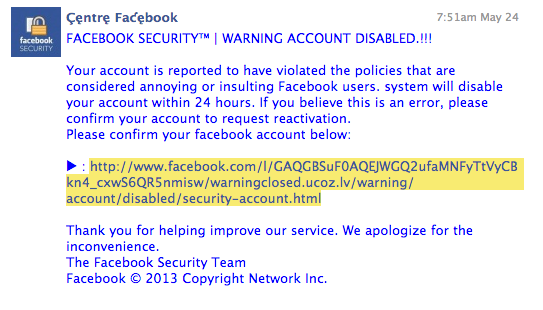
The email has all the typical signs of a phishing email including the bad grammar and the FUD meant to get you to click on the link. The only problem is the link is a legitimate Facebook URL. Confused, I fired up a VM and visited the link, which took me to this page.
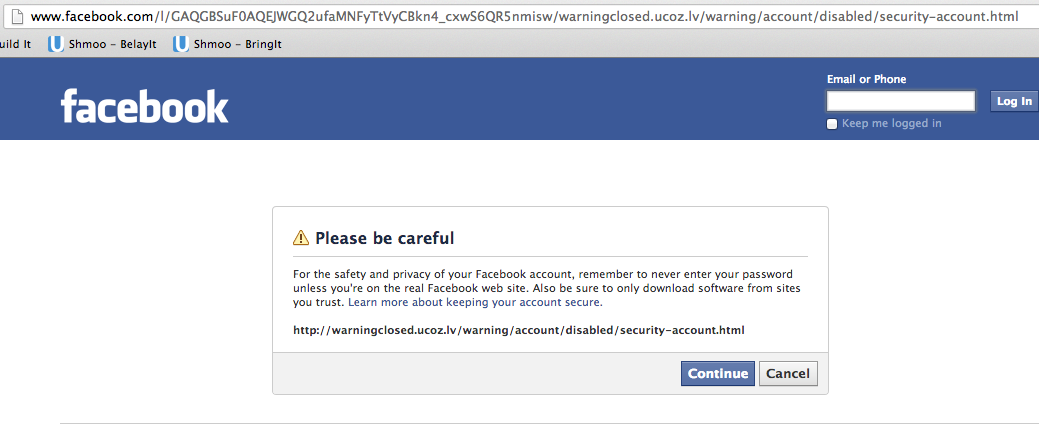
The page appears to be a security warning with a URL at the bottom. I think most Facebook users would see this as normal and click Continue. In fact, the page is designed to let you know you are leaving Facebook to go to the displayed URL but the only indication that you are leaving Facebook is the title of the page.

I thought to myself, "That can't be right, maybe a logged in user gets a different message". So, I created an account and visited the link again. This time I got a warning message letting me know the link was potentially spammy.
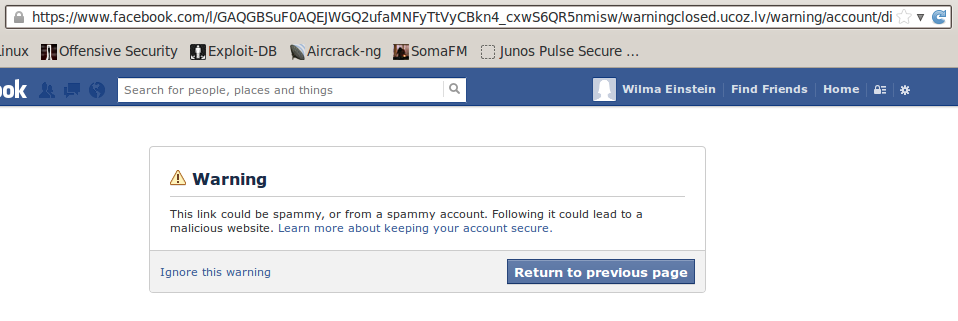
Excellent, Facebook is watching out for it's users and protecting them from spammy links. Not so fast. If you look at the phishing URL closely, you can see it has three parts: http://www.facebook.com/l/, a random string, and the redirect URL. I decide to make some changes to the phishing URL and see what would happen.
If you modify the random string the warning message is no longer displayed because Facebook doesn't recognize this new URL as malicious. This means that Facebook is detecting the malicious link on the full URL and not on the redirected URL. Based on this, it seems that scammers could setup one site and create many different URLs to redirect to this one site and they would likely never be caught by Facebook.
To prevent problems With these type of links, Facebook should make it very clear that the user is leaving Facebook to go to a new site, a message in the page title is not enough. In addition, Facebook should determine if a link is "spammy" based on the destination URL not based on the original URL.
I reported this as a potential bug but Facebook didn't seem to see it as a bug. Maybe I'm crazy, what do you think?